OK, maybe making a donut isn’t that complex, but in a data-driven world, companies are piecing data and AI together to unlock new possibilities to boost profitability, performance, and customer experiences. However, they are often restricted by sensitive data.
The Problem
Players in healthcare, transport, insurance, and finance are strategically positioned to be at the forefront of AI/ML because of their access to huge swathes of data. But often these companies are unable to leverage the full power of data accessible to them – missing out on the efficiencies and monetary gains of AI.A data intelligence report by Seagate highlights that enterprise data is projected to grow annually at a rate of 42%, yet about 68% of this data goes unused.
The remaining 32% of the data that is accessible may be gridlocked by sensitivity restrictions and privacy requirements either by existing policies such as HIPAA or by the data stewards themselves. An AI model with a large chunk of inaccessible data is comparable to putting your dough to fry without oil!
Enterprise data is projected to grow annually at a rate of 42%, yet about 68% of this data goes unused.
Be it a neural network model running facial recognition, or an AI model identifying patterns in financial transactions from a bank, the AI application will only be as good as the scale of data that it can access and infer.
Balancing AI and Data Sensitivity
Analytics leaders need a solution in harnessing their data to its full potential while being careful of data privacy and sensitivity.
For example, a fraud detection ML training model for an insurance company may only require income and payment data from multiple fields of tabular data. However, this tabular data may contain other confidential information such as names, email addresses, employers, and ID numbers.
So how do you minimize exposure of this sensitive data to the AI/ML training or deployment while getting the most relevant results to deliver effective AI? Current methods of data protection such as encryption, masking, removal, and randomizing won’t cut it if you need to retain the integrity of the data quality.
Half-baked AI
Using “half-baked” AI trained on limited or incomplete data can result in:
- Inaccurate Results: When AI models are trained on limited data, they may not have enough information to make accurate predictions or take the right actions. This can lead to incorrect decisions, outcomes, and errors.
- Biased Models: If the training data is biased, the AI model will also reflect that bias. This can result in discriminatory or unfair outcomes, such as denying people opportunities or services based on their race, gender, or ethnicity.
- Limitations in Generalization: AI models that are trained on limited data may struggle to generalize to new situations and data points. This can result in the AI model failing when applied to real-world scenarios that it hasn’t encountered in training.
- Poor Performance: When AI models are trained on limited data, they may not have enough information to optimize their parameters and algorithms. This can result in lower accuracy, speed, and efficiency in their predictions and actions.
On the other hand, protecting customer data is crucial for organizations as it is often private and confidential. According to Verizon’s Data Breach Investigations Report, there were 32,000 confirmed data breaches in 2021 with the healthcare, financial, and retail trade sectors being the most targeted. The cost of each breach can be in the millions and the reputational damage to the company can be devastating.
It’s no surprise technology partners hesitate to provide sensitive data to a third-party AI/ML solution provider without proper measures to protect it. Some industries may also have regulations preventing the sharing of sensitive data. SaaS companies and providers have the opportunity to greatly benefit from AI solutions through leveraging customer data, however, they face challenges with AI and data security due to the cloud environment.
AI systems will at times require access to sensitive data to be fully functional. If the AI system only has access to a subset of the data, the AI model may not perform at it’s required capacity
The development of AI systems will at times require access to sensitive data to be fully functional. If the AI system only has access to a subset of the data (and is blocked from entire groups of other data), the AI model may not perform at its required capacity. Similar to making a donut without all of the necessary ingredients – the final result may be lacking in taste, texture, or appearance, and the donut may not rise or fry properly. In the same way, a poorly trained AI system that lacks access to high-quality and holistic data may produce inaccurate results and undermine confidence in the technology. It is imperative to ensure that AI systems have access to all the data they need to be fully functional, while also taking steps to protect sensitive information and minimize the risk of privacy and security breaches.
Accessing the Remaining Ingredients
Despite the challenges, there are still ways to access sensitive data for AI/ML models in industries.
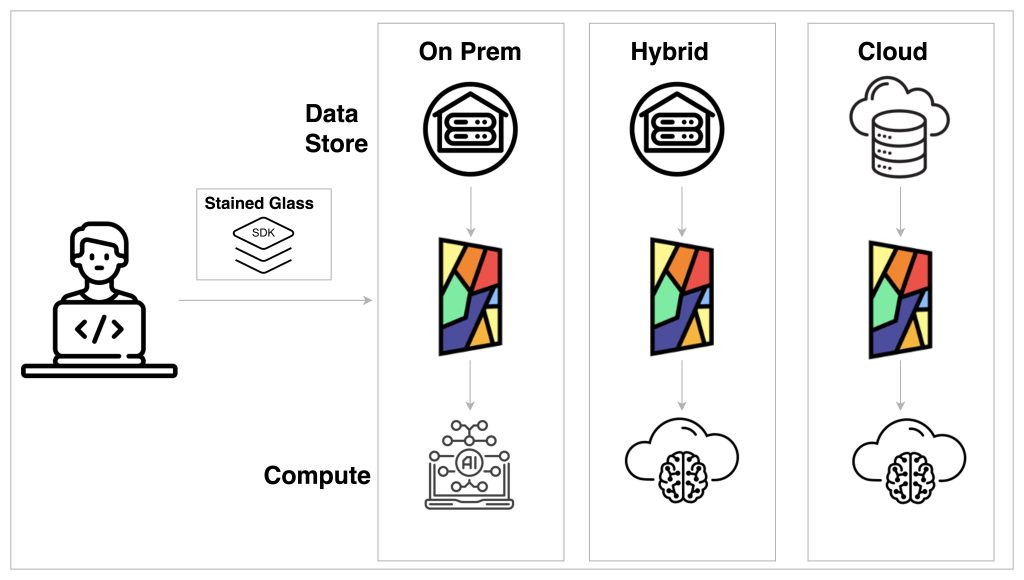
Stained Glass Transform™, developed by Protopia AI, is designed to help AI models access more data while protecting sensitive information. The technology processes data so that only the recipient AI models can read the data – and no one else. The model gains insights without exposing sensitive information. This leads to access to a wider range of sample data, which was previously unavailable.
Instead of providing the target machine learning algorithms with raw, identifiable data, the technology provides an entropied version of the data that is specific and useful only for that particular training or inferencing task. This way, the AI model can access more data without compromising privacy or security.
Organizations can now leverage the full potential of AI and machine learning, providing models with high-quality data while ensuring the protection of sensitive information. Protopia AI acts like a “mixing bowl” that brings all the necessary data ingredients together for the AI model to use in its “baking process” (in this case, frying process) . However, some of the sensitive data is mixed in and no longer identifiable. In this way, Stained Glass™ technology brings all the baking ingredients for a donut together for AI in a secure and controlled manner, enabling the AI to produce high-quality results.
How Stained Glass™ Works
Currently. no other solution transforms data while retaining the same accuracy as Stained Glass. What’s even more remarkable is that it can be used for both model training and AI deployments. Want to learn how Stained Glass does what it does? We won’t disclose the secret recipe here (Ok, no more donut analogies). Get in touch and we’ll show you how we enable responsible and effective AI.