Maximize value, minimize cost
Enterprises are pouring resources into AI, but the cost of keeping sensitive data secure is holding them back. The problem isn’t a lack of GPUs; it’s the way security requirements force those GPUs to sit idle. In this post, we’ll unpack the data risks of AI inference and how “security by isolation” drives up infrastructure costs and eats into use-case ROI. We’ll then break down three real inference hosting configurations side by side, show the cost difference in dollars and compute utilization, and explain a better way to keep data protected without wasting capacity. By the end, you’ll see exactly how to turn security from a cost penalty into a driver of ROI.
Mitigating the data risks of GenAI deployments
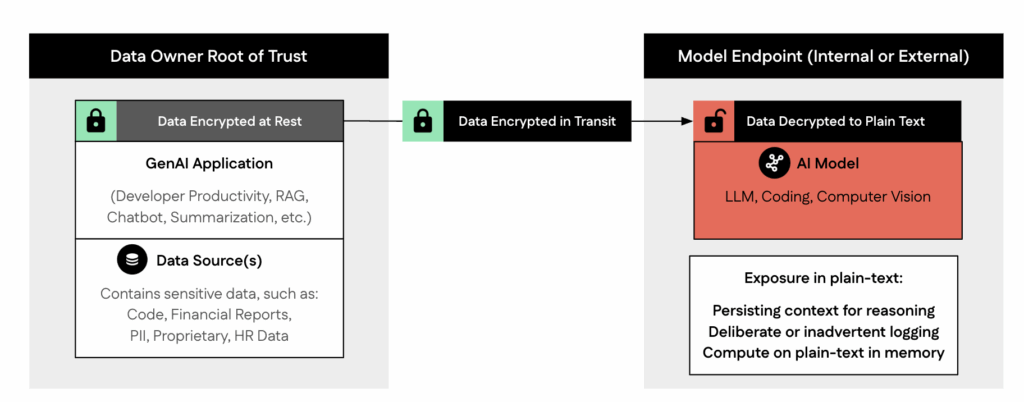
Inference opens up a new risk surface for enterprise data, one that traditional controls for data at rest or in transit were never designed to handle.
Consider some common GenAI applications developed by a global enterprise:
- HR processes employee records and recruiting data.
- Finance runs forecasting and risk models on regulated data.
- IT deploys coding copilots on proprietary source code.
Each team uses its own model. Each dataset is bound by policies and regulations that restrict how it can be used and with whom it can be shared. For example, HR must protect PII in employee records, finance must satisfy SOX audit requirements, and developers must follow internal security policies and zero trust protocols.
It’s the job of the CIO and CISO to enforce these data use restrictions while supporting the needs of the business and making sure infrastructure costs don’t render use-case ROI unjustifiable. That balancing act is relatively straightforward for data at rest, but far less straightforward for AI inference. Encryption protects information in transit and at rest, but during inference, data must be decrypted, leaving prompt and context data exposed in plaintext to the hosting infrastructure. Inputs can surface in ingress and preprocessing, model runtime memory, logs and tracing tools, crash dumps, and temporary caches.
Wasted compute, wasted dollars
This is why, in practice, isolating hardware often means buying and paying for far more GPU capacity than will ever be consumed. Multiple factors play a contributing role:- Global availability: To serve users in multiple regions, GPU capacity must be replicated across geographies.
- Redundancy: Clusters need standby capacity for failover, which requires additional capacity without increasing output.
- Uptime requirements: To meet latency SLAs, models must stay loaded in memory even when demand is low.
- Capacity planning: Enterprises plan for usage spikes to avoid outages, but that buffer often remains unused.
Dedicated deployments must account for these factors and more as they build inference pipelines and provision the required hardware.
The economics of dedicated deployments
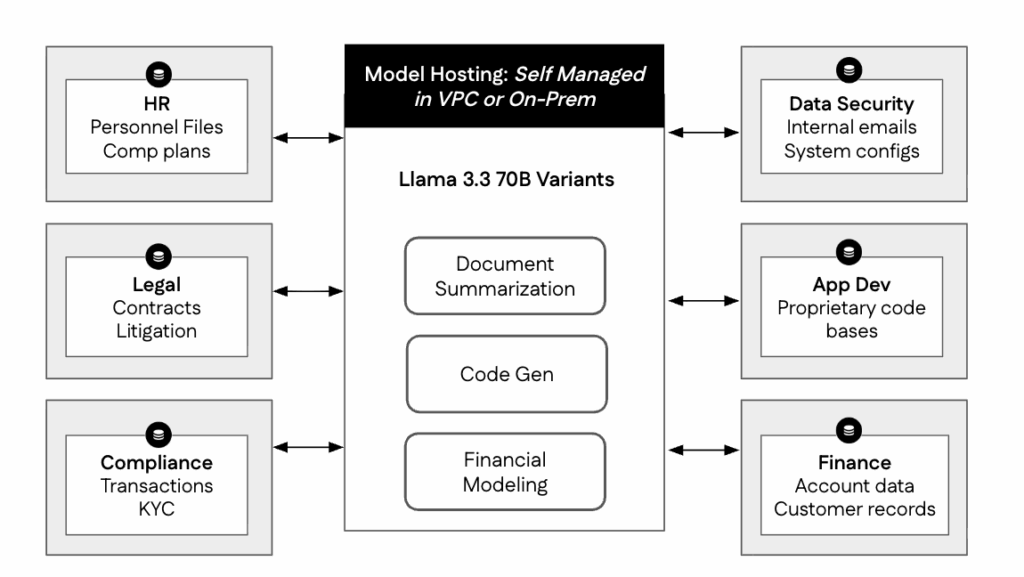
In dedicated deployments, model hosting costs don’t scale linearly with usage. Consider a global enterprise running three Llama 3.3 70B models across different departments: a code-generation model serving a team of global developers, a financial model accessed by analysts across time zones, and a document summarization model used by legal, marketing, and
After surveying departmental workflows, the organization estimates that each user generates roughly 125,000 tokens per day. Scaled across teams, this steady baseline of daily use becomes the foundation for capacity planning.
This token volume is equivalent to a few dozen substantive model interactions per workday; for example:
Code Generation & Review: 40–60 completions or code suggestions such as “generate Python function,” “refactor SQL query,” or “explain this class”; 10–15 inline reviews or docstring generations; 3–5 larger refactors or test-file updates (~500–700 lines total).
Summarization & RAG: Summarize 2–3 contracts or reports (15–20 pages each); 20–40 retrieval or Q&A prompts like “list renewal clauses” or “compare risk terms”; pull 30–60 pages of context from internal sources.
Financial Analysis & Modeling: Generate 2–3 model-driven reports; run 5–10 “what-if” simulations; review 2–4 filings (40–80 pages total); scan 1.5K rows of transaction data to detect trends or anomalies.
The dedicated deployment tax
Running these models on a dedicated cluster requires H100 (or similar) GPUs large enough to meet latency and throughput SLAs, global availability, redundancy, uptime, and usage spikes across all three models. Each model requires consistent performance even when traffic fluctuates, and the infrastructure must be resilient enough to maintain reliability if a node fails or a regional data center goes offline.
Isolated environments can simplify access control and auditability, which is critical for teams handling regulated or proprietary data, but it also means the enterprise owns capacity outright. Whether utilization peaks during development cycles or dips when workloads are light, the GPUs must remain powered and ready. The result: predictable performance, predictable security, and predictable cost—paid 24/7.
The table below offers a closer look at the economics of this “always-on” multi-model enterprise deployment. Tokens represent the total work performed by the model, while GPU-hours measure the compute time required to produce that output. Using the planning rate of 1.25 million tokens per GPU-hour, every 125,000 tokens generated equates to about 0.1 GPU-hour of infrastructure consumption; a simple way to connect user activity to operational cost.
100 Daily Users: 3 x Llama 3.3 70B Models Running in a Dedicated VPC Cluster
|
Tokens Generated |
GPU Hours |
Annual Hosting Cost (USD) |
Effective GPU Utilization |
|
125K |
.1 |
$2,312,640 |
5.2% |
|
312K |
.25 |
$2,312,640 |
12.9% |
|
625K |
.5 |
$2,312,640 |
25.8% |
Higher volume scenarios represent power users running large 70B models continuously to do compute-intensive tasks like full-service code reviews, multi-document summarization, or complex analytical simulations. The result is clear in the numbers: even in higher consumption scenarios, the business is footing the bill for hundreds of thousands of idle GPU-hours, which translates to millions of dollars in compute costs.
How does this translate to my use case?
Costs associated with enterprise deployments are highly variable, and will depend on the SLAs and model usage patterns of your business. Below are the inputs used to simulate the scenario above:
Llama 3.3 70B Model: Representative of a large enterprise-grade open model. Sets the compute scale per replica.
Two replicas per model: Supports uptime, failover, and regional availability; ensures no downtime during maintenance or spikes.
8xH100 Compute per replica: Defines baseline performance and latency expectations for a 70B-parameter model.
15% Redundancy margin: Extra capacity reserved for node or zone failures. Keeps service steady under hardware or network faults.
15% Availability overhead: Headroom for rolling updates, driver patches, and other maintenance windows.
80% Target utilization: The sweet spot between efficiency and performance; prevents latency during bursts.
GPU-hour: Standard compute-billing unit. One GPU running for one hour. 1.25 million tokens = 1 GPU-hour, a conservative planning assumption for modern H100 servers under batched, production-grade inference.
Effective utilization: Consumed ÷ Provisioned GPU-hours. Shows how much of the paid-for compute is actually used for inference.
This common scenario is just one example of how the “isolation-first” approach to security doesn’t just slow projects, it often kills AI initiatives because the required investment in on-prem or dedicated compute environments drives prohibitively low ROI.
Schedule an AI infrastructure ROI analysis to get a detailed assessment of your use case.
The better way: secure, shared AI infrastructure
With Protopia AI’s Stained Glass Transform you can break free from the ROI-destroying “isolation-first” approach once and for all. SGT transforms sensitive inputs into unreadable representations before they ever reach the model hosting infrastructure, meaning sensitive data never leaves the enterprise trust zone. Models still return accurate results, but at no point is the raw data exposed to the hosting environment.
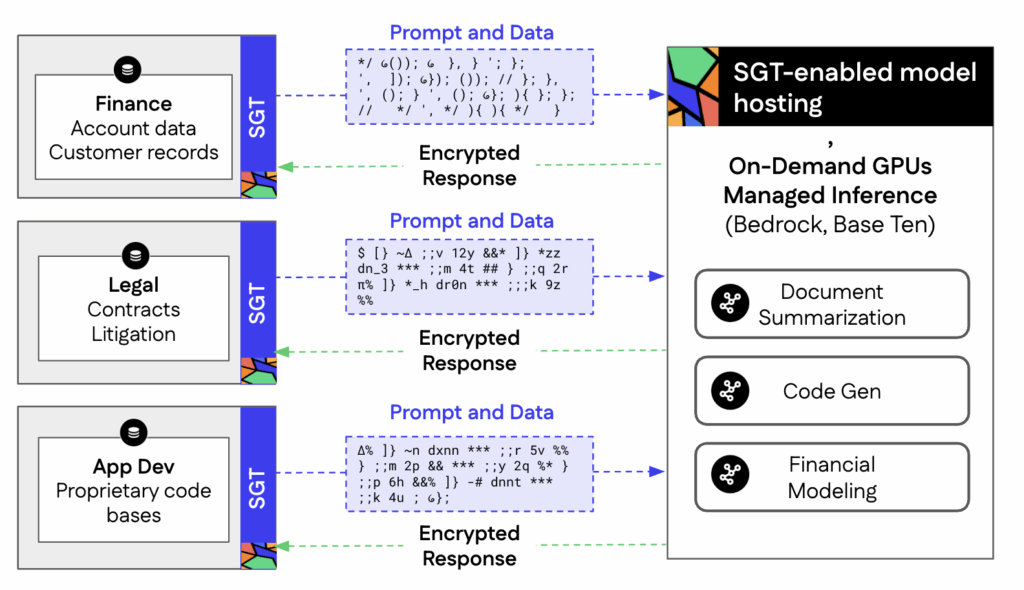
SGT unlocks cost-efficient, highly available and flexible model hosting options, including on-demand GPUs and fully serverless inference by never exposing plain-text inference data to the target infrastructure. Managed services like Amazon Bedrock or Baseten not only free internal teams from the manual work of maintaining model infrastructure, but significantly lower delivery costs.
Instead of paying for reserved H100 capacity around the clock, the enterprise draws from a shared compute pool that allocates GPUs as inference requests come in. When usage dips overnight or certain departments are offline, no GPUs sit idle, which significantly reduces total cost of ownership.

Data privacy that enhances performance
Managed offerings benefit from efficiencies like workload scheduling that maintains high GPU utilization across tenants, and shared infrastructure that distributes operational overhead. Because a warm floor is maintained, there are no cold starts, and latency remains consistent even as capacity scales up and down.
On paper, running on-demand GPUs inside your own tenant seems like the best of both worlds. While sophisticated in-house teams may be able to replicate some of the efficiencies of fully managed-services through custom autoscaling and orchestration, doing so requires specialized engineering, complex monitoring, and ongoing DevOps investment. Fully managed inference services provide these capabilities out of the box, allowing teams to focus on optimizing model performance rather than GPU utilization.
With Protopia Stained Glass, enterprises don’t need to choose between data privacy and efficiency. When data never appears in plaintext, even the most sensitive workloads can run safely in shared inference infrastructure.
Instead of a penalty that drives up costs, SGT turns security into the enabler that unlocks ROI.