Big Win for Secure AI Inference: vLLM Adds Prompt Embedding Support
What the latest feature means for running sensitive workloads with Stained Glass Transforms
vLLM is one of the most popular open-source inference engines available today. Known for exceptional speed, ease of setup, and efficient scaling, vLLM empowers diverse AI teams to serve high-performance large language models. With over 50,000 GitHub stars, it’s the trusted choice for powering applications from chatbots to sophisticated LLM-powered tasks in agentic workflows.
Until recently, vLLM’s input interface presented a significant constraint: models could only accept plain text prompts or token IDs. This configuration limited the ability to preprocess sensitive or proprietary data before it reached inference infrastructure and required custom forks of the vLLM container to support workflows like that required for roundtrip inference data protection by Protopia AI.
This is no longer a barrier with the latest update to vLLM. The new prompt_embeds parameter allows models to accept arbitrary vector representations as input, while retaining compatibility with optimizations like PagedAttention and continuous batching which is all you need to integrate Stained Glass Transform capabilities to your LLM deployments.
For Protopia customers and partners, this is a key enabler for secure, private inference. vLLM’s prompt_embeds functionality makes it easy to integrate Stained Glass Transforms (SGTs) directly into LLM pipelines without modifying model serving architectures or retraining. With SGTs in place, teams can run sensitive AI workloads without exposing plain-text prompts or outputs on cost-efficient, shared infrastructure while preserving the high performance vLLM is known for.
Enabling secure inference with Protopia Stained Glass Transforms
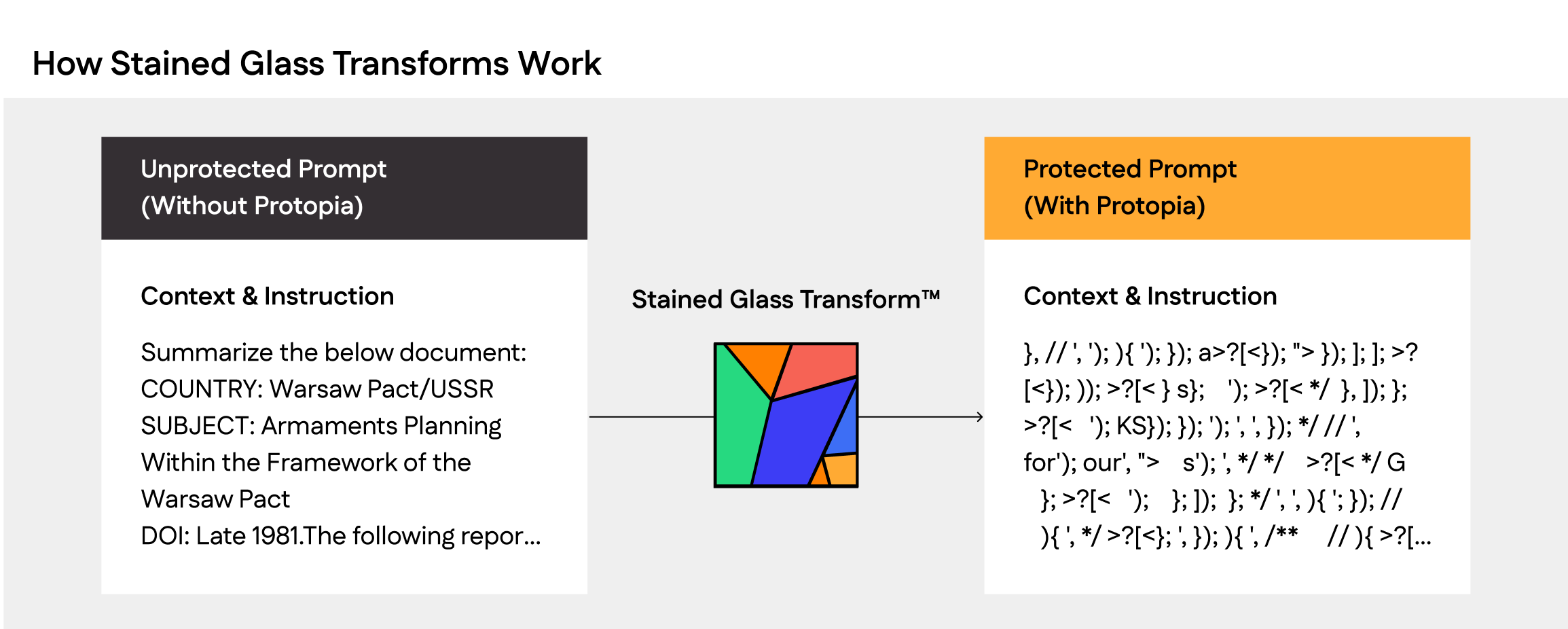
Under the hood, SGT applies a stochastic, non-invertible transformation to each input, which means if you run the exact same prompt through SGT multiple times, you’ll get different embeddings every time. This randomized re-representation using Stained Glass Transform ensures that unauthorized access to the vectors cannot revert to your plain-text sensitive data.
By generating stochastic embeddings entirely on the client and sending only those protected, transformed embeddings to vLLM, SGT eliminates any risk of a data leakage from the inference pipeline. This significantly shrinks your inference attack surface while enabling the use of sensitive information where it wasn’t possible before. In combination with vLLM, Protopia SGT ensures no plain-text or token IDs ever touch the server.
Figure 1: Unprotected plaintext prompts (left) are transformed by Protopia’s Stained Glass Transform into irreversible, stochastic embeddings (embedding reconstruction shown on right), ensuring no human-readable data ever touches the model serving infrastructure during inference.
Protopia’s SGTs work seamlessly with standard decoder‐based models and vLLM, enabling users to deploy in self-hosted or managed environments with minimal added configuration. Learn more in our product sheet.
Privacy-enhanced LLM endpoints for managed inference providers
Many inference endpoint providers run vLLM under the hood as a key component of their LLM serving infrastructure. Integrating SGTs via prompt_embeds makes it easy for managed services to offer private inference as a first-class feature without alterations to model architectures or underlying serving infrastructure.
With SGT-enabled inference endpoints, customers seeking to protect sensitive data during inference can maintain privacy of customer prompts when using hosted LLMs even in shared-tenant environments. By removing the need to reserve dedicated GPUs for every data owner’s sensitive data, inference endpoint providers or AI-native application developers building on managed inference endpoints, can significantly boost infrastructure utilization using concurrency, improve margins, and unlock new revenue.
Figure 2: Side-by-side Python notebook comparison of Protopia’s SGT integration with vLLM. The left panel shows a standard plaintext prompt input, while the right panel demonstrates how Stained Glass Transform produces irreversible, stochastic embeddings passed via the new vLLM prompt_embeds field, ensuring only protected vectors reach the model-serving infrastructure.
With Roundtrip Protection + Lambda, enterprises no longer have to choose between price, performance, and privacy. Enterprises can now achieve all three and accelerate their time to value with LLMs.
Technical benefits of Protopia + vLLM prompt_embeds
Effortless integration: Easily enable SGTs to pass to vLLM via the prompt_embeds field by activating the enable-prompt-embeddings flag.
No Disruption to Model Pipeline: No retraining, no model updates required. vLLM fully supports prompt embeddings in both offline and OpenAI-compatible server (via /completions endpoint) modes.
Preserves throughput: vLLM processes prompt embeddings just like normal inputs, fully leveraging its PagedAttention, batching, quantized kernels, and speculative decoding with no impact to latency.
Get started with Protopia using vLLM Prompt Embeddings
To learn more about how to enable prompt_embeds in vLLM, refer to the following resources:
→ vLLM Tech Docs:Read the official vLLM guide on prompt embeddings.
→ Talk to a Technical Expert: Connect with our engineering team to integrate SGT into your vLLM pipeline and unlock secure, high-speed inference today.