As enterprises rush to adopt Large Language Models (LLMs) and Generative AI capabilities, executives face a dilemma. According to Gartner, 54% of senior technology and business leaders believe mishandling and leakage of sensitive and confidential data in Generative AI systems are critical concerns.
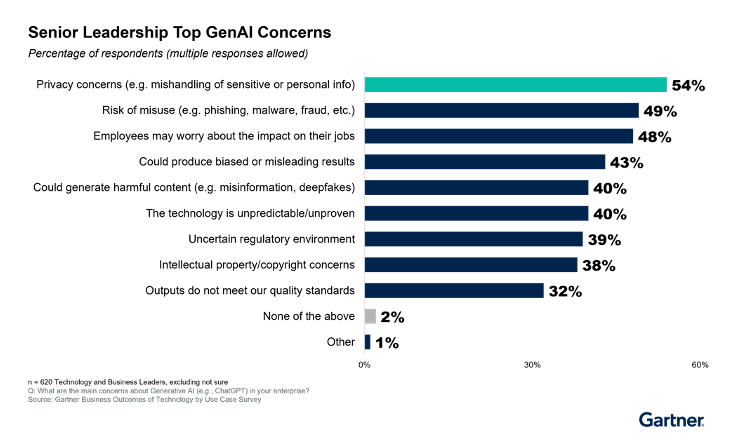
Figure 1 – Top GenAI Concerns for Senior Leaders, Gartner Survey from Executive Pulse: Organizations Are Not Prepared for Generative AI Risks — And They’re Running Out of Time
The challenge becomes even more acute as increasing customer demand and strategic mandates require that technology leaders rapidly develop AI capabilities within their organizations.To build these, these leaders need to tap into the organization’s proprietary, high-value data, which is increasingly viewed as a strategic asset, even a competitive “moat”, for building impactful AI innovation.
AI systems are composed of many interacting components and their data flows expose organizations to a complex web of security, privacy and compliance risks. Many companies respond by keeping their sensitive data secured and off-limits to AI systems. As a consequence, impactful AI use cases don’t get addressed and rapid product development is blocked, hampering competitiveness.
Organizational AI projects face another fundamental challenge due to security related constraints. To protect their high-value data assets, companies may be forced to run their AI models and workloads on-premise or on dedicated compute infrastructure. This can have dire consequences on the cost and speed-to-value of their AI initiatives.
In this blog, we will examine how Protopia can help make more of your most valuable data accessible for increased AI efficacy. We will explore the modern AI and LLM application stack, explain how organizations classify their data assets, touch upon risks at each layer that limit data availability. Finally we will see how Protopia can empower you to increase availability of your most valuable data securely and unlock access to the most performant compute environments for greater speed and cost-effectiveness in running AI applications. We also share an infographic on how Protopia integrates with and secures your AI infrastructure.
A layered view of the AI application stack
While real AI systems are complex and comprise a multitude of subsystems, it is helpful to abstract these to a set of core ‘layers’ that combine to form the typical modern AI application.
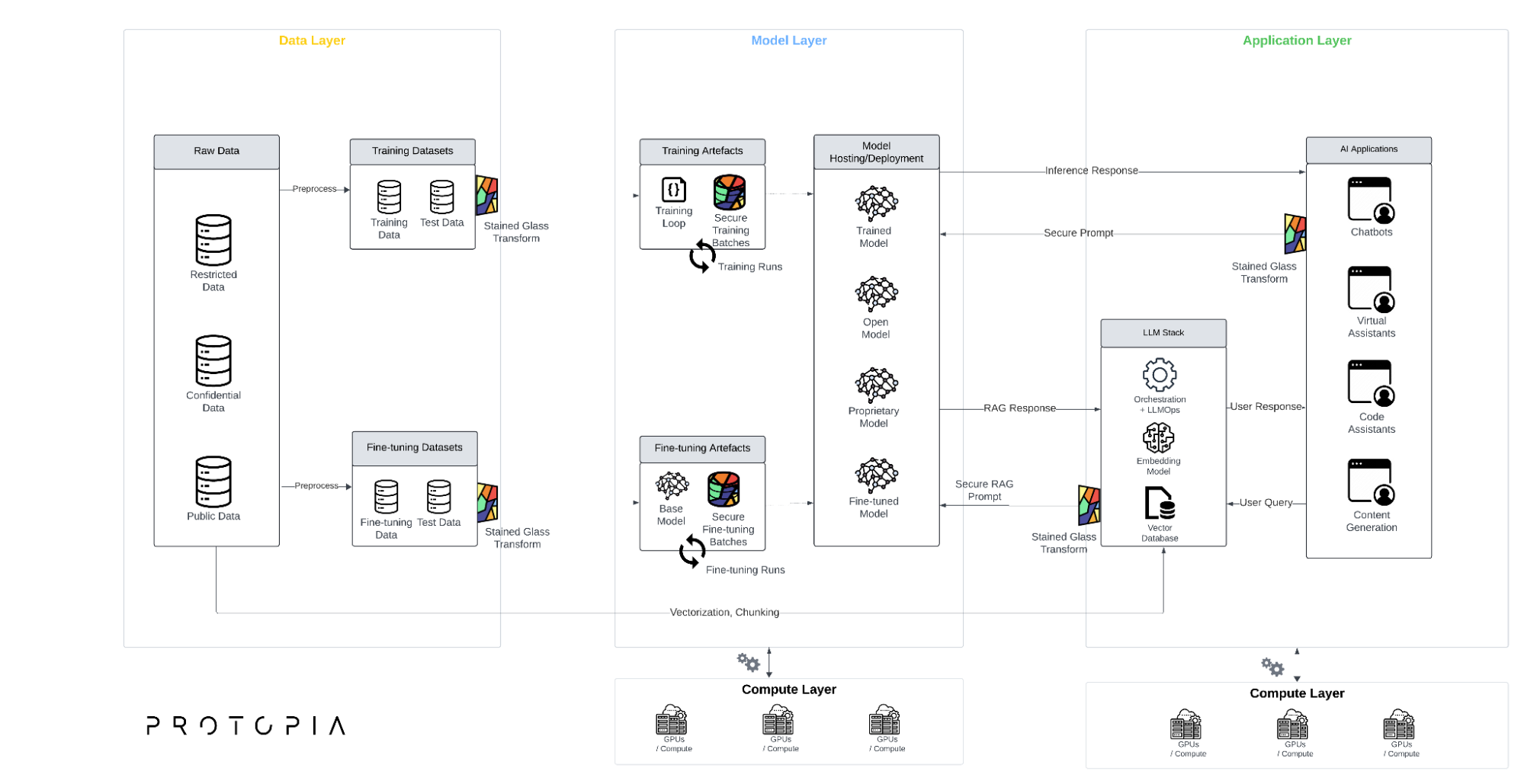
Figure 2 – AI Application Layers with Protopia
Data layer
At the foundation of any LLM application is the data layer. This is where raw data – company business plans, design blueprints, customer information, financial records, product specifications, employee data, etc – is stored, processed and converted into datasets suitable for model training and fine tuning. The data layer is where much of the heavy lifting happens in terms of data engineering – data is extracted from source systems, transformed to align with the target data model, and loaded into a centralized data store or data lake. From here, data scientists and ML engineers can access the data they need to train and fine tune their models.
While data is the lifeblood of AI systems, it is also the most sensitive and risk-prone asset of organizations. An organization’s competitive advantage, security, governance, integrity and compliance depends on how well it understands data risks and manages them. It is helpful to think of data classification to understand and navigate the risk landscape.
To classify data, we can take two approaches – risk-based classification, and value-based classification. Organizations employ extensive controls on their data systems specifically for risk-based controls.
Risk-Based Classification
To manage critical business data and comply with prominent regulations like GDPR and CCPA, organizations tend to classify their data assets based on degrees of sensitivity and the corresponding security requirements:
- The most important category would be sensitive data, such as personal, financial or healthcare information of personnel and customers, which is governed by data privacy regulation like GDPR and CCPA. A breach of such data could result in criminal or civil penalties, identity theft and financial losses. Such data is often subject to the highest levels of scrutiny, governance and security.
- Internal data, including organizational documents, revenue details, product designs, strategic plans, etc must remain private within the organization, as their leakage can create reputational damage or competitive disadvantages. These require appropriate access controls and security protocols.
- From a compliance perspective, public data, such as marketing materials and product descriptions, generally does not necessitate stringent security measures. Such data is publicly available.
These are broad categories and organizations assign their risk-based classifications differently based on their own risk assessments and compliance needs. We cover the value-based classification in more detail in the next section. Enterprise data is susceptible to a host of risks, ranging from data leakage, privacy violations, data tampering, deliberate attacks to model poisoning and more. We will cover these risks, mitigation strategies and how successful technology leaders overcome these challenges in much more detail in the coming weeks. Subscribe to our blog to receive the content in your inbox.
Model layer
Moving up the stack, we have the model layer. This is where the magic happens – data and code are brought together in training or fine-tuning runs, with the goal of producing performant models.
In the more popular trend, enterprises start with a pre-trained, open-source base model, like Llama-2, Mixtral7B, Gemma, DBRX, Phi, Gemma and others. They fine-tune the models on their own domain-specific data. Fine-tuning lets them adapt these models to their own use cases, with more accurate outcomes, better performance and in many cases, lower total cost of ownership.
As enterprises strive to unlock the transformative potential of artificial intelligence (AI), a critical consideration emerges – the compute infrastructure required to train, fine-tune, and host AI models. This infrastructure hinges heavily on the sensitivity of the data powering the AI system. The degree of sensitivity of the data affects the security controls and choice of infrastructure. This can profoundly impact the speed at which organizations realize value from their AI investments.
Value-Based Classification
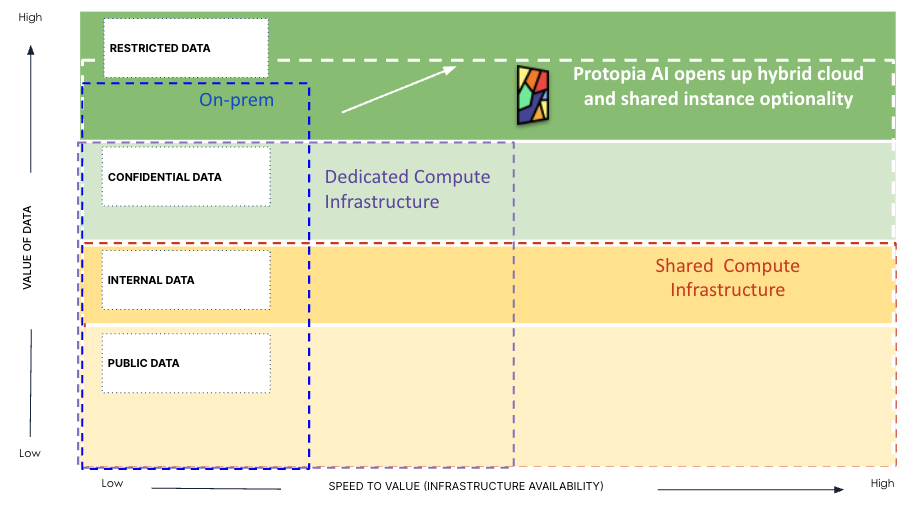
Figure 3 – Value-based Classification of Enterprise Data Assets
We noted earlier that a firm’s data assets offer strategic advantage. Organizations often classify and control access based on the ‘value’ of the asset to the firm’s business overall. This classification should encompass the following categories:
- Restricted Data: At the highest echelon lies restricted data, encompassing proprietary source code, product specifications, trade secrets, research/designs, and financial records. Such data underpins the company’s competitive advantage and existence. These assets often require case-by-case approval for access and utilization.
While this type of data holds immense potential for driving business value through AI, it is often kept on-premises or in highly secure cloud data platforms, with stringent access controls and robust security measures in place. Organizations also tend to limit the deployment of AI applications utilizing this data to on-premise environments, contending with the growing challenges of procuring and managing the necessary GPUs and infrastructure, thereby significantly reducing the speed at which AI projects operating on this sensitive data can deliver value. - Confidential Data: Next in the hierarchy is confidential data, encompassing organizational documents, revenue details, product designs, and strategic plans. Access to this data is restricted to a select group of individuals for very specific use cases and permissions.
This type of data carries high value for organizational AI initiatives, as it can be used to unlock AI-driven strategic endeavors. However, due to the sensitivity of the data, the corresponding AI applications are often run on dedicated GPUs/compute resources. Dedicated instances incur higher costs, lower scalability due to caps on available resources, and increased maintenance overhead compared to shared compute infrastructure. Due to these reasons, running AI applications on dedicated compute may dramatically slow down time to value compared to running them on shared infrastructure. - Internal Data: Forming the third tier of valuable assets is internal data, such as internal documents, scientific research data, geographic information, market research findings, etc, which include information used by internal employees but not intended for public consumption. This class of data has lower sensitivity and can be leveraged more freely within the organization for AI initiatives.
Organizations often run AI applications that consume this tier of data on shared compute infrastructure, balancing lower security requirements with the cost and scalability advantages of a shared environment. - Public Data: Finally, public data, such as news articles, open-source software, public datasets, and public domain multimedia, resides on the internet and is freely accessible to anyone. This non-sensitive information is what most organizations are comfortable using AI applications with today. However, since this data is available to everyone, it is least likely to create competitive advantage. Although it can be used to create some organizational efficiencies, being restricted to using this class of data with AI is unlikely to generate the return on investments in AI that enterprise leaders will need to demonstrate.
Application layer
This layer reflects systems underpinning real-world applications – chatbots, content generation tools, virtual assistants, and more.
End users interact with these applications via natural language queries or commands. These queries are then passed down the stack, triggering a complex series of interactions between the application, the LLM orchestration layer, the model itself, and the underlying data.
In cases where the application directly queries the model, inference requests are sent via API calls to the hosted model.
In Retrieval Augmented Generation (RAG) scenarios, user requests are managed by an LLM application layer that includes a variety of technologies and components to orchestrate data/prompt flow to models. Vector databases are often used to store and search through the embeddings produced by embedding models/layers, enabling fast retrieval of relevant information.
How Protopia expands data availability while minimizing risk
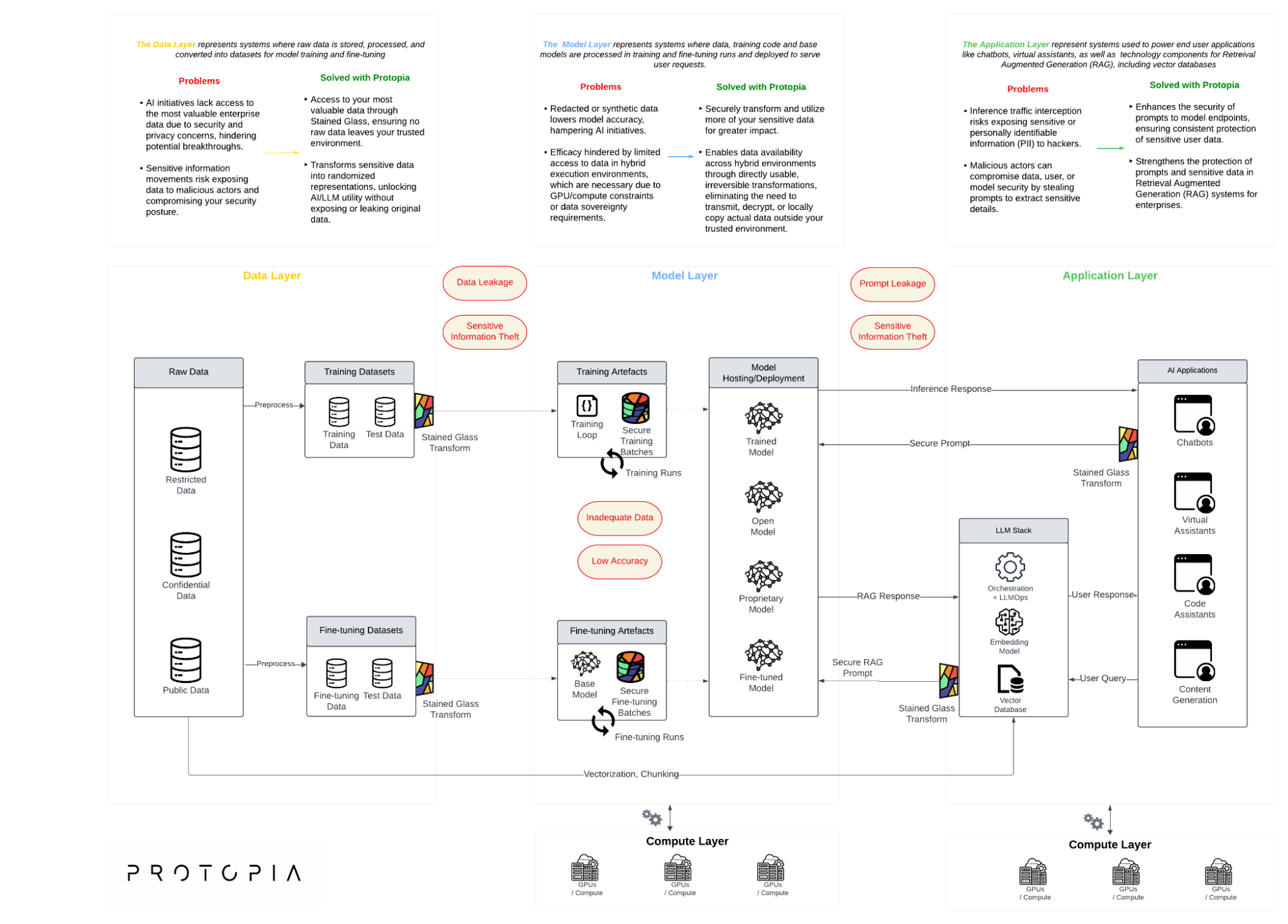
Figure 4 – Infographic. Download Full Version
Protopia AI’s Stained Glass Transform™ (SGT) converts unprotected data to a randomized re-representation. This representation is a stochastic/randomized embedding of the original data that preserves the information for the target LLM without exposing unprotected prompts/queries, context, or fine-tuning data. This re-representation is a one-way transformation that can’t be reversed, ensuring holistic privacy of enterprise data and protection against leaking sensitive information to the platform, infra, or humans fine-tuning or deploying the LLM. SGT is complementary to existing redaction/masking as well as existing encryption. SGT’s applicability is not limited to language models. Randomized re-representations can also be generated for visual and structured data. You can dive deeper into how Protopia works in this blog.
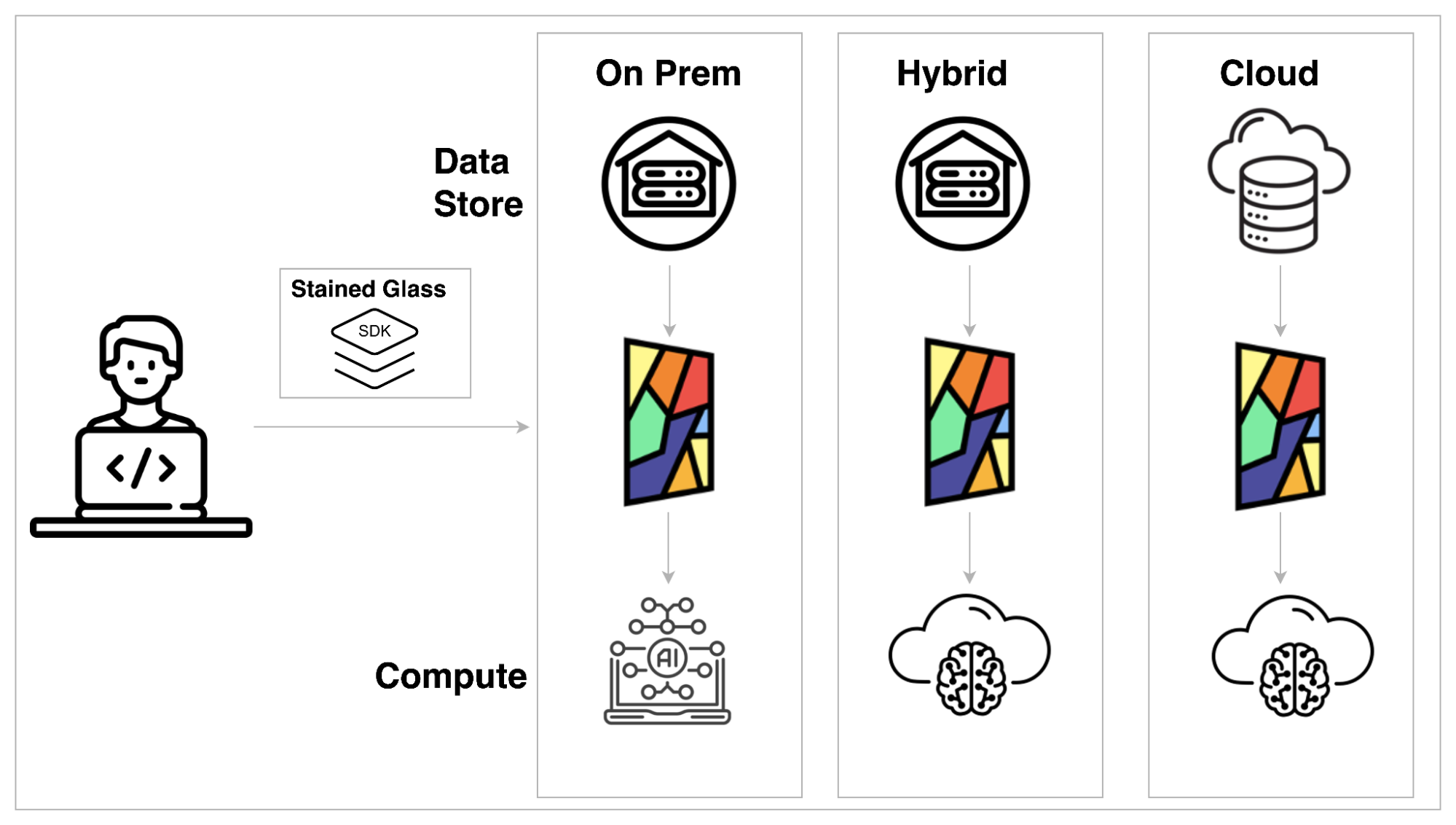
Figure 5 – Protopia Flexibly Supports Multiple Deployment Scenarios
Let’s examine how Protopia solves for common blockers and risks to expand your AI capabilities at each layer.
| Data Layer | |
| Problems (Data Leakage, Sensitive Information Theft, etc) | Solution |
| AI initiatives lack access to the most valuable enterprise data due to security and privacy concerns, hindering potential breakthroughs. | SGT lets you access safe representations of your most valuable data while ensuring no raw data leaves your trusted environment. |
| Sensitive information movements risk exposing data to malicious actors and compromising your security posture. | Sensitive data is transformed into randomized representations, unlocking AI/LLM utility without exposing or leaking original data. |
| Model Layer | |
| Problems (Poor Model Accuracy, Insufficient Actual Data for Fine-tuning or Training, etc) | Solution |
| Redacted or synthetic data lowers model accuracy, hampering AI initiatives. | SGT lets you fine-tune or train models with randomized representations without sacrificing accuracy. |
| Efficacy hindered by limited access to data in hybrid execution environments, which are necessary due to GPU/compute constraints or data sovereignty requirements. | Enables data availability across hybrid environments through directly usable, irreversible transformations, eliminating the need to transmit, decrypt, or locally copy actual data outside your trusted environment. |
| Application Layer | |
| Problems (Prompt Leakage, Sensitive Information Theft, etc) | Solution |
| Inference traffic interception risks exposing sensitive or personally identifiable information (PII) to hackers. | Enhances the security of prompts to model endpoints, ensuring consistent protection of sensitive user data. |
| Malicious actors can compromise data, user, or model security by stealing prompts to extract sensitive details. | Strengthens the protection of prompts and sensitive data in Retrieval Augmented Generation (RAG) systems for enterprises. |
We hope this blog gives you a deeper understanding of the modern AI application layers, how organizations employ risk-based and value-based classification methods to represent their data. Finally, we introduced Protopia AI’s Stained Glass Transform and discussed how it helps tackle problems and unlock secure AI at every layer of the stack.
You can access the full infographic here. To learn more about how Protopia can help to secure your LLM stack, please contact our team of experts.
