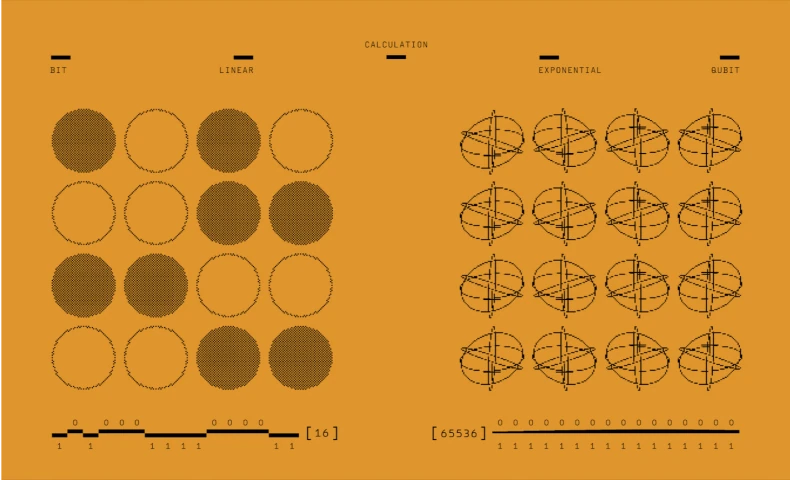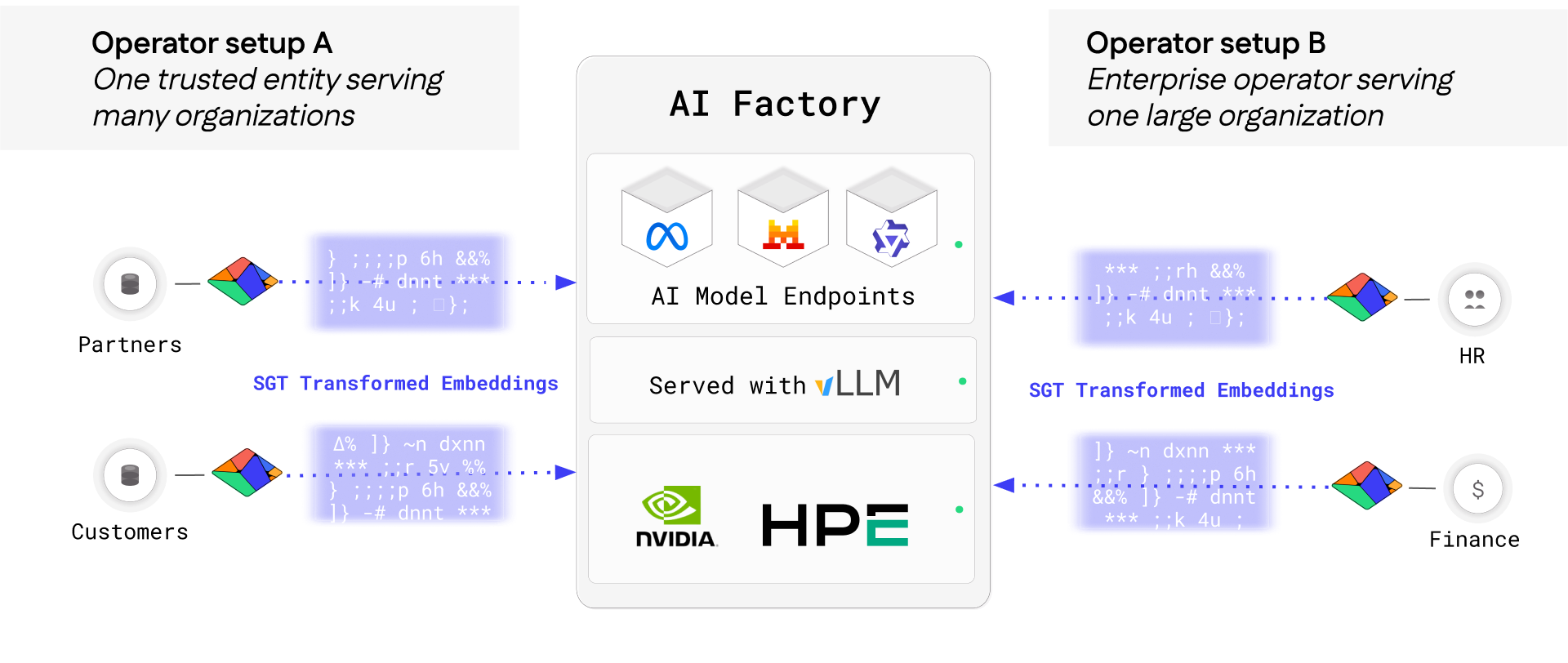
AI-as-a-Service

Sovereign AI

Enterprise
Model Training

Model Validation