HPE and Protopia AI unveil architecture for trustworthy AI Factories
AI factories are becoming the default architecture for enterprises consolidating workloads across business units, AI-as-a-Service providers, and sovereign clouds. The model depends on two requirements working together: outcomes, meaning AI working with the data that matters most at full fidelity, and cost, meaning those outcomes delivered at a cost-per-token that makes the platform viable. The challenge is that the data driving the best outcomes is often the most sensitive data an organization holds. Much of it is restricted from AI entirely. The rest gets routed to dedicated carveouts that fragment capacity and drive up cost. Three compounding factors explain why roughly half the AI Factory ends up sitting idle:
-
- Data tax: PII, PHI, financial records, proprietary code, and other sensitive inputs are restricted or must be de-identified, destroying contextual utility.
-
- Infrastructure tax: Operators allocate dedicated hardware carve-outs to avoid plaintext exposure, fragmenting capacity and raising cost-per-token.
-
- Deployment tax: Compliance cycles, procurement friction, and isolation requirements slow or kill high-value use cases before they reach production.
Most operators never hear about the use cases that die before deployment. Customers have been conditioned to accept dedicated infrastructure as the only path for sensitive data. The demand is there. It’s just suppressed.
Encryption ends where the AI Factory begins
All three taxes stem from inference-time plaintext exposure. Even with encryption at rest and in transit, models must see plaintext during inference, which leaves sensitive data exposed in logs, memory, and snapshots reachable via misconfiguration, compromised credentials, or lateral attack. As a result, tenants either avoid sensitive data, strip it of value, or demand dedicated infrastructure.
Multi-tenant scheduling does not help: it governs who gets compute, not what is visible in the data flowing through the platform.
From ROI killer to platform growth driver
Through the Unleash AI with HPE program, HPE and Protopia AI have validated an operational blueprint that changes this calculus. The Trustworthy AI Factory blueprint combines:
-
- HPE and Protopia AI validated an operational blueprint that lets operators safely run regulated, sensitive workloads on shared infrastructure. Core components: AI factory (at scale and sovereign): a consolidated platform that centralizes model training, fine-tuning, and inference, while enabling secure, multi-tenant support for regulated workloads especially when combined with Protopia AI’s Stained Glass Transform™ (SGT)and HPE AI Services.
-
- HPE Private Cloud AI on NVIDIA-accelerated hardware: the production AI factory platform.
-
- Protopia AI’s Stained Glass Transform™ (SGT): an inference privacy layer that transforms sensitive data into stochastic, model-usable protected representations before it leaves the tenant boundary, ensuring plaintext never reaches the AI Factory environment.
-
- The HPE AI Services portfolio includes packaging, integrating, and operationalizing the blueprint across tenants for both HPE Private Cloud AI and AI factory. HPE Services will also offer SGT creation as a training output, delivering Stained Glass Transforms alongside trained models so tenants can deploy private inference on any infrastructure, including HPE Private Cloud AI, AI factory, or inference services.
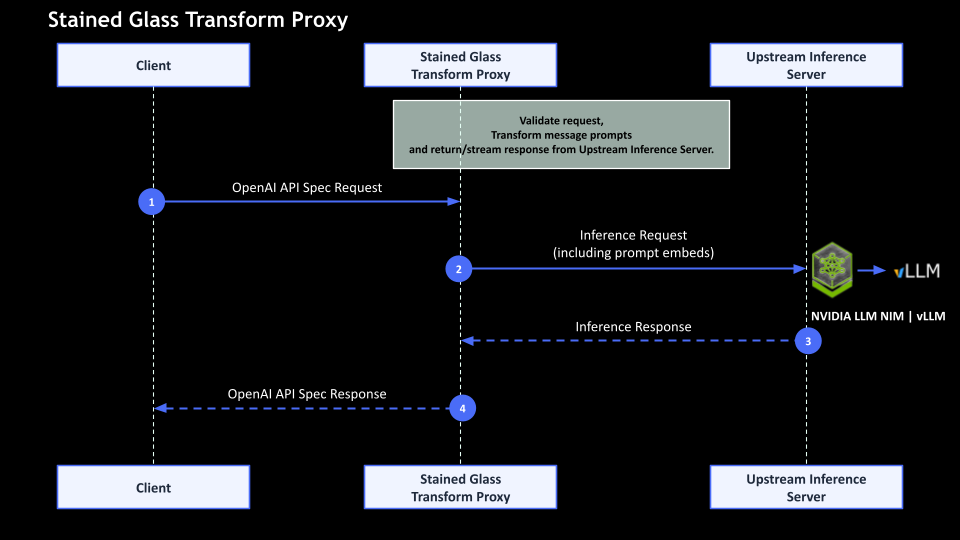
How Protopia AI’s Stained Glass Transform™ (SGT) works
-
- An SGT sits at each tenant’s data root of trust and converts sensitive prompts (documents, records, code, clinical data) into irreversible, model-specific protected representations before leaving the tenant boundary.
-
- The AI factory receives only protected representations, so logs, memory, and snapshots never contain tenant plain text.
-
- This approach integrates with existing inference servers (e.g., NVIDIA LLM NIMs, vLLM) and preserves model utility with near-identical accuracy and negligible latency impact.
-
- Multi-tenancy controls, RBAC, observability, and quota mechanisms continue to function, applied to protected representations rather than raw data.
Economic and operational benefits
For operators, the economics shift in three ways. First, workloads that required dedicated carveouts move to shared capacity, and GPUs that were reserved for a single tenant now serve many. Second, use cases that were killed at the business case stage become deployable, turning every sensitive workflow that comes online into incremental token volume. Third, regulated industries that previously required dedicated infrastructure become addressable on the same shared platform.
AI Factory operators need to support sensitive workloads on shared infrastructure without forcing customers into dedicated carveouts that undermine platform economics. Our technical validation of Protopia Stained Glass on HPE Private Cloud AI confirmed what we needed to see: model accuracy retention, production-grade throughput, and seamless latency scaling. This gives our customers a practical path to serve high-value workloads that were previously too costly or too restricted to deploy.
Deployment patterns supported
-
- Enterprise AI hub: Multiple business units use share AI Factory capacity while keeping sensitive data under local control. Teams handling PII, PHI, financial records, or proprietary IP run on common PCAI infrastructure without dedicated carveouts, because only protected representations reach the platform.
-
- Operator-run inference farm: Sovereign AI providers, MSPs, and telcos serve regulated customers without taking custody of customer plaintext. Each customer runs SGT at its own data root of trust. Only protected representations reach the operator’s platform, opening demand from regulated markets that previously required dedicated infrastructure.
-
- Shared training facility: Tenants train custom models on AI Factory infrastructure and leave with both the trained model and a Stained Glass Transform, a portable inference privacy layer that makes the model deployable for sensitive use cases on any infrastructure without requiring dedicated hardware.
-
- Partner validation and inference: Enterprises hosting proprietary models on PCAI can serve those models to partner organizations without either party exposing sensitive data to the other. Each partner runs SGT locally, sending only protected representations to the enterprise model. One platform serves multiple partners with no plaintext exchange.
The operators who can offer private inference on shared infrastructure will capture the workloads and customers that others are still waiting to be asked about. The blueprint is ready. The question is who moves first to capitalize on higher utilization, lower cost-per-token, and access to regulated markets previously locked behind dedicated infrastructure.