Unlock the value of your enterprise data without exposing it during retrieval or inference
Why “Private” in RAG Still Isn’t Private Enough
Retrieval-Augmented Generation (RAG) is the go-to pattern for grounding LLMs in your own data, keeping responses relevant, and unlocking real productivity. However, these high-value data assets are also high-risk, usually housing proprietary information or sensitive PII, health data, or financial records.
It is for this reason that most high-value enterprise data continues to go unused. Even the most “secure” AI stacks stop short: they protect data at rest (disk encryption) and in transit (TLS), but not in use. The moment your embeddings are queried, or your prompts and context leave your environment for an LLM API, they can be exposed.
For regulated industries like finance, healthcare, government, and defense, that gap is a dealbreaker.
Bottom line: In-use protection is the missing piece.
Combining Strengths for End-to-End Confidentiality
By combining CyborgDB and Protopia Stained Glass, you can address both halves of the “in-use” problem:
- CyborgDB encrypts embeddings at rest, in transit, and at search time, keeping retrieval confidential.
- Protopia Stained Glass obfuscates embeddings and prompts before they leave your trust boundary so even the LLM never sees raw sensitive data.
Together, these layers create a privacy lifecycle from user query to model response.
How It Works
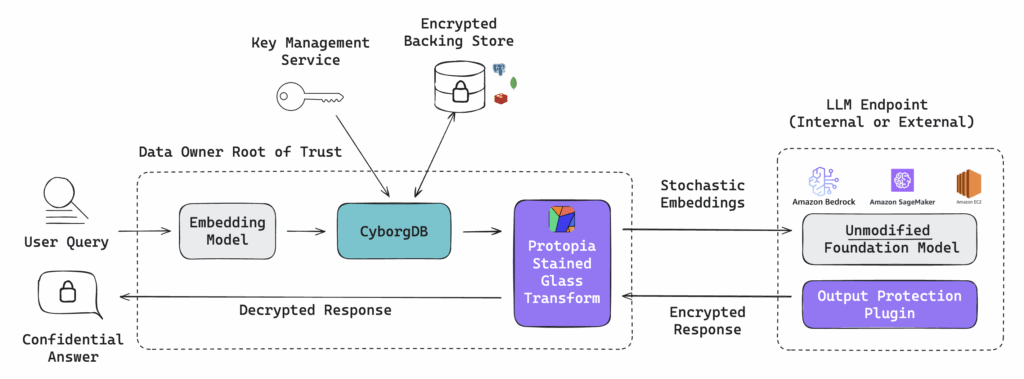
The architecture below shows how confidential retrieval and private inference fit together in a single RAG pipeline:
1. Embed inside your trust boundary.
The user query is converted to embeddings locally by your embedding model.
2. Confidential retrieval with CyborgDB
- Embeddings are searched while encrypted.
- Keys are managed via your KMS/HSM.
- Works with standard backing stores (Redis, Postgres, MongoDB).
- Per-index keys enforce multi-tenant isolation.
3. Private inference with Protopia
- Top-K results are combined with the query and a system prompt.
- The combined prompt/context is passed through Stained Glass, producing stochastic embeddings.
- Works out-of-the-box with popular LLMs
- SGTs can be created for any open model or fine-tuned variant
- Millisecond-level overhead, near-baseline accuracy.
4. Call an Internal or External LLM endpoint
Works with internal or external model hosting (AWS Bedrock, SageMaker, etc.).
Optional output protection plugin to transform responses.
5. Return a confidential answer.
Decrypted inside your secure environment, with no plaintext prompts or retrieved content ever leaving.
Why This Pattern Works Well
- True end-to-end coverage. Retrieval and inference are both protected.
- Performance-friendly. GPU-accelerated retrieval and lightweight transforms keep inference speeds fast.
- Infrastructure-ready. Integrates cleanly into existing workflows & backends.
Private RAG doesn’t have to be theoretical. With confidential retrieval and private inference in one workflow, you can deliver AI that meets strict security demands and performs in production.
Schedule a 1:1 session with an AI security engineer to evaluate your AI stack and learn how to build a production-ready, end-to-end private inference pipeline with zero data exposure.


