The More of It Your AI Factory Runs, the More Value It Can Create.
Agentic AI has moved from demo to job description. The long-running agents enterprises want to deploy are persistent, always-on digital workers that reason across systems, write and run their own tools, and carry multi-step work to completion. At GTC Taipei, NVIDIA heralded the arrival of useful AI agents, and Jensen’s data center math, “the more you buy, the more you make,” follows from it.
A single agentic task can consume significantly more tokens than a one-shot prompt, and a fleet of always-on agents needs that capacity around the clock. That is the workload an AI factory is built to deliver, and it is why utilization, throughput, and the tokens you turn into revenue are now the numbers that decide whether the factory delivers value.
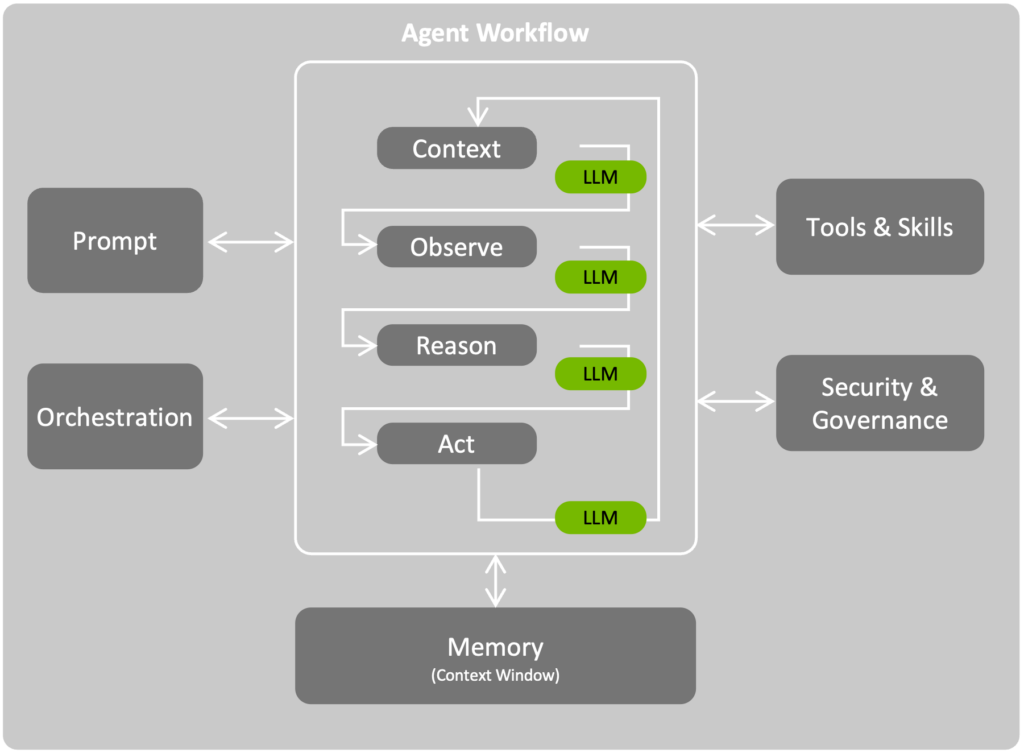
NVIDIA published the reference design for running these agents more securely, the Secure Agent Workspace. For an operator, the part worth reading closely is near the end: “Inference is a hard dependency for any agent loop — every tool call requires tokens. It [i.e., inference] is not a feature of Secure Agent Workspace itself; the workspace integrates with it. The two are architecturally separate.”
That dependency creates an opportunity that can scale substantially. A single agent task is not one model call. The loop reasons, calls a tool, reads the result, and reasons again, many times before the task is done, and each pass requires more inference. If you run an AI factory, whether for the business units of your own enterprise or for the customers you provide capacity to, the goal is to support the inference workload and maximize AI factory’s utilization and output. The more of that work it runs, the more it earns.
Where That Work Goes Today
So where does that inference actually run? An agent reaches a model one of two ways: on a GPU close to the workspace, or through a managed inference endpoint it calls over its brokered, allow-listed path. The economics point to the managed endpoint on a shared, multi-tenant AI factory, because that is where the capacity and the cost efficiency live.
But there is a catch. The data owner, whether a business unit, a team, or an external customer, does not manage that factory. Even when the enterprise itself operates the multi-tenant infrastructure, the business unit whose data is sitting in the prompt does not. So today, the endpoint an agent is allow-listed to call is usually not the shared factory at all. It is usually a tightly controlled, single-tenant deployment the data owner already trusts. The workspace governs the agent, but it cannot govern what happens to the data once the request leaves on its journey to the model.
And when that data is sensitive, source code, a customer record, a transaction history, an underwriting packet, the exposure is not only to the GPU. Inference servers log request payloads. Serving frameworks cache prompts and spill to disk. Observability pipelines capture inputs. Schedulers record metadata, and traffic crosses fabric between racks. Every one of those is a standard part of how a serving stack runs, and each is a place where plaintext sensitive data would sit in the clear on infrastructure the data owner does not control. Confidential Computing (CC) addresses part of this, and we return to it later, but CC is scoped to the GPU’s execution environment and its attested boundary. Many application-layer surfaces sit outside that boundary, no matter how the GPU is configured.
So, the sensitive work gets routed away from the AI factory and onto those single-tenant carve-outs instead. The data stays safe, but the factory is inefficient. That gap is the isolation tax. It is not only an architecture problem, but also revenue the factory cannot earn, because its most valuable and token-heavy workload cannot safely run on it.
Bringing the Sensitive Work to the Factory
Almost every reason that work gets exiled traces back to a single fact: the factory would see the data in plaintext. So, change that one fact. If the sensitive data isn’t sent as plaintext, it avoids ever being logged, cached, or exposed, and the work can run there like anything else.
That is what Protopia AI’s SafeCLAW does – makes the inference integration safe for sensitive data, so the work that was previously paying the isolation tax can route to the multi-tenant factory like everything else.
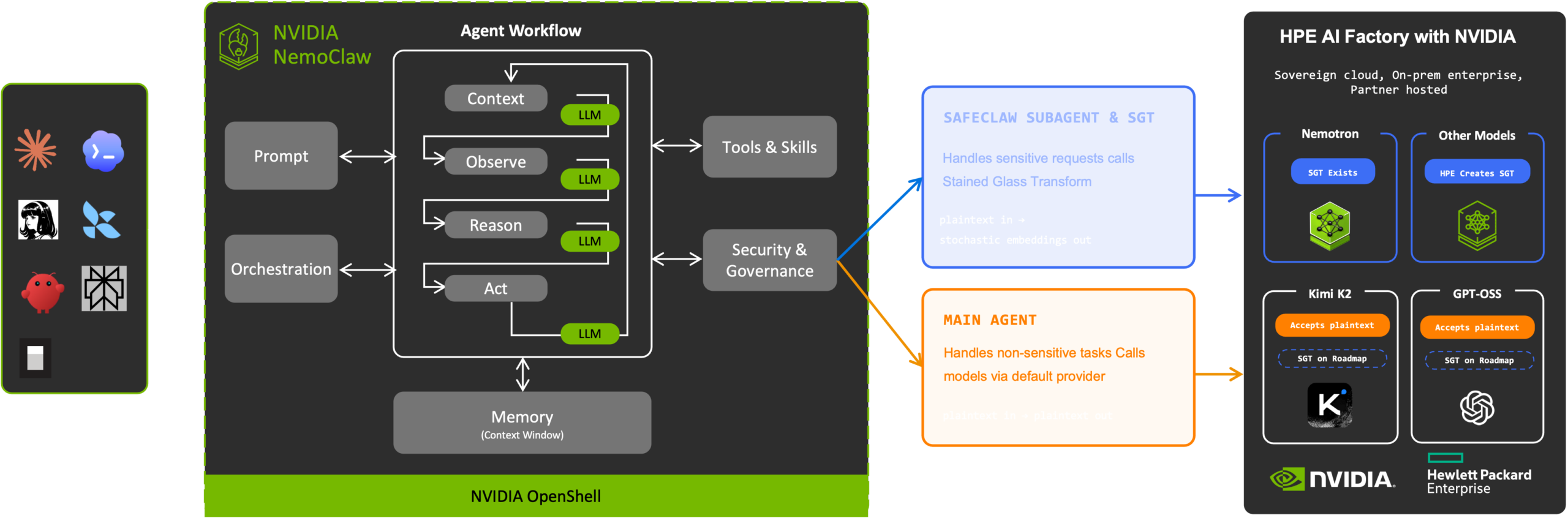
This is how it works: it runs inside NVIDIA OpenShell, the runtime that governs the agent. OpenShell’s Inference Policy decides how each model call is routed, per request and per sensitivity class. Non-sensitive calls from the main agent, regardless of which harness you run, OpenClaw, Hermes, Claude, Codex, go the ordinary way, plaintext in and plaintext out. Designated sensitive calls are delegated to SafeCLAW, a subagent that routes inference through a Stained Glass Proxy running as a sidecar in the same stack. The proxy applies Protopia’s Stained Glass Transform (SGT), converting the prompt and its context into a stochastic representation before any of it leaves the data owner’s trust boundary. OpenShell defines the policy syntax; Protopia provides the transform and the proxy as the target it routes to. There is no fork of OpenShell, just SafeCLAW integrated into the agent harness of choice.
Now, what reaches the model is only the stochastic representation. The model reasons over it directly, with no key and no reversal step anywhere on the host. Because the transform happens upstream, every downstream component, every log, cache, trace, metadata record, and fabric hop, only ever handles the stochastically transformed form. A misconfigured log, a compromised observability agent, or a container escape yields nothing recoverable, because as designed, the plaintext was never there to begin with. This is a property of where the data is transformed, not a runtime policy that depends on every component behaving, and a security team can confirm it by inspecting the serving layer itself. As discussed later, NVIDIA Confidential Computing complements this on the AI factory by locking down the model execution environment, which is especially important when a proprietary frontier model is the one being served.
Stained Glass Transform protects the entire inference input data path, the prompts, documents, and context flowing into the model. That is the exposure that has previously kept sensitive agentic work off multi-tenant factories, and it is the exposure SafeCLAW is designed to address. This is the stack that the HPE Services team has been instrumental in building, turning OpenShell and SafeCLAW into turnkey agentic workflows for IT, finance, and retail.
NVIDIA Nemotron Gives the Work an Endpoint to Target
For any of this to be useful, the target model on the factory has to be able to read the stochastic representation as it arrives. NVIDIA Nemotron™ is a family of open AI models built for long-running agentic work and Protopia collaborated with NVIDIA to build a Stained Glass Transform (SGT) for NVIDIA Nemotron 3 Super.
The model itself is not retrained, it is the SGT that trained to ensure the stochastic representation is natively readable by Nemotron. Protopia’s Stained Glass Engine is designed to enable any model owner, proprietary frontier, or open, to create an SGT without altering the model.
With the transform built and an embedding endpoint enabled, an agentic call can route to a Nemotron endpoint on an AI factory and come back with a useful answer, while the factory only ever sees the stochastic representation of the data. One agent stack can then point at any SGT-enabled Nemotron endpoint, whether deployed inside the enterprise, in a sovereign cloud region, or operated by a partner for burst or spot capacity. The effect worth noticing is that the trust posture converges across all three. On-prem, sovereign, and partner-hosted normally carry very different risk profiles, but when the only thing any host ever sees is a stochastic embedding, the risk posture is more consistent across environments, and the choice becomes one of cost and capacity rather than data exposure.
What the Operator Gets Back
For whoever runs the factory, this directly benefits the utilization math. The sensitive agentic workflows that were previously being sent to single-tenant, isolated business-unit carve-outs can now run on the multi-tenant factory like everything else. Carve-outs tend to pin a factory at lower effective utilization, while true multi-tenant operation swings it back toward the higher utilization range.. The valuable, high-token agentic reasoning the factory was built to absorb is exactly the work the isolation tax was keeping off it. Remove that barrier and the work becomes viable, on hardware already paid for. This helps make “the more you buy, the more you make” hold true: nothing is artificially keeping the most valuable workloads off the machine that was bought to run them.
Where Confidential Computing Fits
To help enterprises achieve secure, trusted, and efficient AI production, NVIDIA has been publishing comprehensive reference architectures, for Secure Agent Workspaces and for Confidential Computing using Confidential VMs and Confidential Containers. Stained Glass Transform complements Confidential Computing and Secure Agent Workspaces to protect sensitive data across the entire inference data path in the AI factory. Together they support an end-to-end approach to data and model privacy across the entire inference stack.
At GTC Taipei, NVIDIA and Protopia AI showed this running.
The Secure Agent Workspace reference design and NVIDIA OpenShell provide autonomous agents a governed place to run. Protopia AI SafeCLAW and Stained Glass Transform then extend that governance to the inference data path, and the SGT for NVIDIA Nemotron gives the sensitive work a real endpoint to route to on any AI factory. The HPE Services team unveiled a HPE Discover, NVIDIA OpenShell with SafeCLAW, across IT, finance, and retail workflows on an AI factory.
These are the everyday cases where an agent has to read a sensitive ticket, a ledger, or a customer record to be useful at all, which is exactly the work that has been hardest to place on multi-tenant infrastructure. It is the same architecture, in production form, running work that has been challenging to run on multi-tenant infrastructure.
Ready to unlock private agents for your AI factory?
Get Started

