Authors: Kyle Mylonakis, Abhishek Ratna, Andrew Sansom, Jennifer Cwagenberg, Eiman Ebrahimi
Open large language models (LLMs) continue to gain traction in enterprise organizations due to their customizable responses and cost efficiencies. Rapid innovation cycles are narrowing the performance gap between open models and leading closed LLMs, creating a rich set of options. Enterprises, AI infrastructure providers, and LLM application builders are increasingly considering, comparing, and making selections among open and closed models.
In this blog, we demonstrate how Protopia AI creates Stained Glass Transforms (SGTs) to maximize the protection of sensitive data when working with popular open models. We provide a step-by-step exploration of the principles, creation, and benchmarking of an SGT on NVIDIA DGX Cloud. Additionally, we present a secure Retrieval-Augmented Generation (RAG) implementation using Protopia AI on Oracle Cloud Infrastructure (OCI), developed in collaboration with the OCI AI Launchpad team.
Securely harnessing your data with open-source LLMs
To harness the full potential of open models and develop useful AI applications, companies must leverage their organization’s proprietary data or establish secure channels for partners and providers to access it. Understandably, organizations exercise caution in utilizing their valuable data assets, particularly when integrating with AI platforms.
To address legitimate concerns about data privacy and ownership, particularly in cloud environments, industry-wide initiatives like the OWASP Top 10 for Large Language Model Applications have emerged. These guidelines help organizations implement AI technologies safely while mitigating data privacy risks.
As organizations meet data security best practices, more collaborative AI projects become feasible. Teams increasingly seek to collaborate between organizations or even departments within a single entity. This collaboration necessitates the secure use or sharing of data.
Protopia AI’s Stained Glass Transform (SGT) addresses this need. SGT empowers organizations to harness AI’s potential without compromising data security. By transforming data in a way that avoids exposing plain-text representations, SGT ensures businesses maintain full control and ownership of their information. This approach significantly reduces the risk of data leaks, enabling organizations to explore and benefit from developing AI applications that were previously infeasible due to data privacy concerns.
We created an SGT data protection layer for a state-of-the-art Mistral 7B model by accelerating Protopia AI Stained Glass Engine (SGE) using NVIDIA DGX cloud. The approach is outlined in the following sections and can be applied to any target LLM. By enabling enterprises to narrow the attack surface at the data layer, SGT unlocks the ability to leverage strategic data with the most efficient GPU capabilities available for their applications.
Semantic Information Preservation in LLM Vector Embeddings
Modern LLMs work by iteratively sampling the next words or tokens (word fragments) from a probability distribution based on the previous words. For this sampling to be useful, a very accurate probabilistic model of language is required. This model is provided by a specific type of neural network called a decoder-only transformer, which produces the conditional probabilities (or more accurately, the logits) of the next token given an input sequence of tokens.
All neural networks, including transformers, operate on real vector data. Therefore, the input text is first converted into sequences of integers (tokens), and then those token sequences are converted into sequences of vector embeddings. These embeddings act as the input for the language model, with a one-to-one relationship between the vector embeddings and the input text. In such deterministic vectorization, the same input text will always be transformed into the same set of vector embeddings. Due to the one-to-one correspondence between the tokens and the deterministic vectors, the original tokens are easily accessible by a lookup table mapping the tokens and embeddings to each other.
Because of this, using deterministic embeddings does not provide any rigorous data security benefit. Organizations require a secure solution for sensitive data to not be exposed in plain-text for language modeling tasks.
Privacy-preserving Data Transformation with Stained Glass Transform
Protopia AI’s SGT is an operator that converts data into stochastic representations while maintaining its utility for LLM tasks. Specifically, the SGT for text employs a probabilistic approach to maximize the distributional divergence between input vector embeddings and their transformed counterparts. Simultaneously, it minimizes the utility loss of these transformed embeddings for language modeling. This capability enables the use of significantly different randomized representations of the input, replacing deterministic input embeddings during the generation process.
Fig 1: Unprotected tokens in plain-text data and prompts are transformed to secure representations that preserve full utility for LLM operations.
SGT offers several key advantages:
- Data privacy: SGT decouples ownership of plain-text data from the LLM implementation and infrastructure, enhancing data protection.
- Retention of semantic meaning: As demonstrated later in this blog, SGT representations perform nearly identically to plain-text representations when evaluating common LLM benchmarks.
- Computational efficiency: The transformation process is numerically inexpensive, requiring significantly less time than overall generation. This efficiency allows Stained Glass Transform to run on commodity hardware, such as CPUs, close to the data source. Consequently, enterprise data owners can maintain ownership of plain-text representations while leveraging powerful, scarce GPU resources for fine-tuning or generation tasks wherever these GPUs can be availed efficiently.
- Low latency: SGTs can be integrated into existing training loops with negligible impact on training throughput. Unlike alternative data privacy methods such as encryption, which often introduce significant latency into training pipelines, SGT’s vector transformations involve relatively simple computations that easily overlap with existing GPU processing time.
By combining data privacy preservation with computational efficiency, Stained Glass Transform empowers enterprises to harness the full potential of LLMs while maintaining control over their sensitive data assets. This solution enables enterprises to utilize powerful generative AI tools without compromising data governance or regulatory requirements.
Creating SGTs with Stained Glass Engine
An SGT is generated by executing a training job using the Stained Glass Engine (SGE). This process learns the function that performs stochastic transformations on input vector embeddings. The training job utilizes a pre-trained foundation model and resembles a fine-tuning process. However, instead of adjusting the pre-trained model’s weights for a specific task, SGE trains the parameters of layers dedicated to stochastic transformations.
Importantly, SGT is trained with the target LLM without altering the foundation model’s weights. By doing so, the transform can learn to preserve the utility of the transformed embeddings for language modeling tasks while maximizing the distributional divergence between the input vector embeddings and the output transformed embeddings.
SGE empowers machine learning engineers to extend and augment their existing training loops to create an SGT. Users can seamlessly integrate their models with SGE through API calls. Behind the scenes, SGE leverages PyTorch hooks to modify and compute the loss function used in SGT training, manage data flow between the transformation and the model, and optionally implement memory-saving optimizations. By utilizing PyTorch hooks, developers can produce transforms without altering the model’s core code. This streamlined process is illustrated in Figure 2 below.
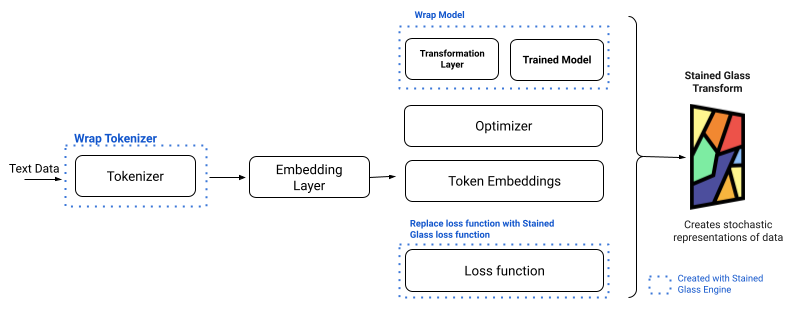
Fig 2: Stained Glass Transforms are created using SGE from the existing base model components without modifying their underlying code.
Stained Glass Engine (SGE) supports any PyTorch module and Hugging Face Transformer, allowing for seamless integration into virtually any training loop. Once the integration with SGE is complete, SGTs are trained using the same runs and frameworks the user already employs for normal training/fine-tuning and model creation. Internally, SGE performs an optimization that balances maintaining the utility of the original model and the strength of the SGT being created. As the SGT itself is a machine learning model, it has hyperparameters that define the balance during the creation process using SGE.
Accelerating SGT Creation on DGX Cloud
DGX Cloud provides access to customizable, pre-tuned GPU clusters–the power of a supercomputer in the cloud–which can accelerate the creation of Stained Glass Transforms (SGTs). Depending on the desired dataset, target model for SGT creation, and required turnaround time, users can quickly choose their training job configuration (e.g., 2 nodes with 16 GPUs or 8 nodes with 64 GPUs) to optimize time-to-value. Additionally, the pre-configured scripts available on the DGX Cloud nodes make running Stained Glass Engine (SGE) with distributed training seamless and efficient.
To create an SGT using SGE on DGX Cloud, first upload related artifacts either via the DGX Cloud CLI or the DGX Cloud UI:
- Upload data
- Upload a container that contains SGE and all required dependencies
- Configure secrets used for logging experiments and model store
Next, configuring an SGE job with the desired CPU(s), GPUs, number of nodes, mounted storage, secrets, and the desired container image.
Users can also configure their jobs to persist additional data on the cluster. During SGE training, DGX Cloud automatically provides visualizations to monitor, evaluate, and optimize resource utilization.
Leveraging SGT with Mistral-7B without a reduction in model quality
Training Configuration
We created a Stained Glass Transform for Mistral-7B-Instruct-v0.2, an instruction-tuned language model using the OpenOrca dataset from Hugging Face. OpenOrca contains annotated conversations between humans and AI assistants for training and evaluating AI models in open-domain dialog tasks. This dataset was used to produce the SGT due to its diverse content and relatively modest size.
Training was performed across 13 epochs of this dataset using AdamW with modern transformer optimizer settings. The training took place on 48 A100 80GB GPUs hosted on 6 nodes with 8 GPUs each on DGX Cloud on OCI. The base Mistral model was cast to bfloat16, and flash-attention 2 was used for attention computations. The Stained Glass Transform was trained in single precision with SDPA attention provided by PyTorch.
Eluther AI’s evaluation harness
Eluther AI provides an open source Language Model Evaluation Harness that aggregates industry and academically standard benchmarks for evaluating language models across a wide variety of tasks. This evaluation repository contains dozens of the most widely used metrics for gauging language model performance in areas such as question answering, common sense reasoning, and advanced topics like mathematics, sciences, and law. Hugging Face’s previous language model leaderboard evaluated models on HellaSwag, MMLU, ARC, and TruthfulQA. Eluther AI’s training harness provided mechanisms for easy evaluations of these metrics.
Utility Benchmarking
Training a Stained Glass Transform (SGT) is inherently a multi-objective problem where the objectives of data utility and data privacy are simultaneously optimized. Data utility is measured by the SGT’s ability to preserve the underlying model’s capability to accomplish its tasks. For language models, these tasks are quite general and span a wide variety of aspects. Hugging Face provides a leaderboard of LLM models evaluated on MMLU, HellaSwag, ARC, and TruthfulQA. We calculate the zero-shot variant of these metrics, as they are generally regarded as more difficult and more representative of the use-cases of an SGT. The results of these metrics are summarized in Table 1. As the table shows, the randomized re-representations of the embeddings created by SGT maintain near identical performance to their plaintext counterparts in industry standard benchmarks.
| Model | Data Protection Metric (Mean Tokens Transformed) | HellaSwag | MMLU | Truthful QA | ARC |
|---|---|---|---|---|---|
| Mistral w/ Stained Glass | 98.44% | 76.67% | 55.39% | 67.90% | 51.02% |
| Mistral w/o Stained Glass | 0% (i.e. Plain-text exposure) | 76.53% | 57.21% | 68.27% | 50.94% |
Table1. Utility and Obfuscation Results of Mistral + Stained Glass Transform
Data Protection Benchmarking
The output of a Stained Glass Transform (SGT) consists of randomized embeddings that do not appear in the embeddings table. These embeddings have many different text representations. To evaluate the level of privacy protection offered by the SGT, we use various statistical algorithms to attempt decoding the transformed embeddings back to text. One such algorithm is a nearest neighbors search, which maps the randomized embeddings to the closest embedding corresponding to a token in the vocabulary. The computed nearest neighbors are then mapped back to their token representations using the embeddings table.
We compute several different token reconstruction attempts for every example in the evaluation dataset, in this case, the OpenOrca dataset discussed earlier. We then compute the minimum number of transformed tokens across the reconstructions as the data protection metric for each example in the dataset. Let xij represent the number of tokens transformed of the i-th evaluation dataset example by the j-th reconstruction attempt, then our data projection metric is
meani(minj(xij)).
The mean across all examples in the evaluation dataset for the data protection metric is reported in Table 1. As the table shows, with SGT, over 98.4% of tokens are transformed on average across all examples from the evaluation dataset which signifies the high level data protection added by SGT while still retaining model utility.
Secure LLM/RAG implementation blueprint on OCI
The AI Launchpad on OCI simplifies the deployment of cutting-edge AI and machine learning solutions by offering pre-trained models, MLOps tools, IoT integration, and a user-friendly interface for enterprises to harness OCI’s powerful GPU infrastructure.
The images below demonstrate how SGT secures a RAG system built with the AI Launchpad, integrating data protection into AI automations and models like Mistral 7B. With SGT, the ChatBot now safeguards instructions, context, and documents retrieved from the vector database or uploaded in real-time.
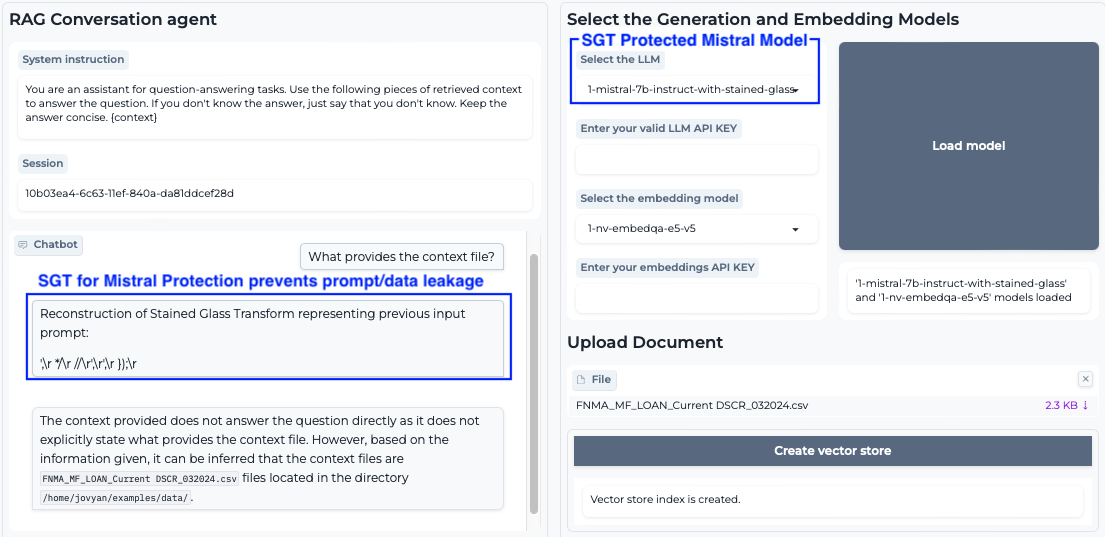
Fig 3: SGT Protected RAG/LLM on Oracle CIoud Infrastructure AI Launchpad
Conclusion
The Stained Glass Engine and NVIDIA DGX Cloud present compelling solutions for enterprises aiming to maximize the potential of LLMs while retaining ownership of their sensitive data assets. We demonstrated how to seamlessly train Stained Glass Transform for Mistral 7B as an example of how SGTs can be created for any target AI model. By showcasing how data can be transformed into stochastic representations that preserve utility for LLM tasks, we present a robust approach to privacy-preserving LLM deployments. This capability is used in OCI’s SGT Protected RAG/LLM implementation. SGT unlocks new AI applications that were previously inaccessible due to data privacy concerns by ensuring data remains secure and thus solves a critical challenge in the adoption of generative AI technologies.