In the last century, most of an organization’s data was housed in what could be the next dinosaur of office furnishings – the locking file cabinet. These humble cabinets provided basic security for everything from one’s performance (and behavior!) in fifth grade to run-of-the-mill phone records or life-changing medical tests. The low-security drawers housed this data for a person with the right key to use the needed record, whether they were a school coach, police detective, customer service rep, or top-notch surgeon.
Today’s file cabinets are the virtual repositories of data that an enterprise owns and secures, even as they expose select data to authorized users. Data collected is often wide-ranging and purpose-driven. Typically, these enterprises are made up of different departments, each one owning some silo of the organization’s data. In a forward-moving enterprise, each department would expect to extract value from the data they own and from other internal departments to positively impact their organization. They may even work with third-party machine learning or AI service providers to further their vision, exposing select data to outside vendors to complete an initiative. Unfortunately as the figure below illustrates, more often than not, companies are inhibited from utilizing AI to extract the full value of the data they have access to because of internal risk governance protocols and/or external regulations.
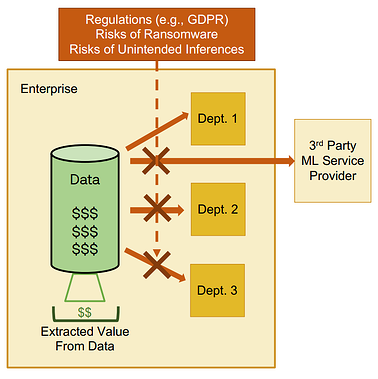
Each time an organization shares the data they own, whether to internal departments or third-party service providers, there is a risk that data will be breached or compromised. The question: “how secure/risky is the AI we want to deploy?” is one that is often asked at the very end of the initiative before pulling the final trigger and can bring everything to a screeching halt. This is a great example of where the entire process (from data prep to extracting final value) could go faster/smoother if these gatekeeper questions were addressed by design from the start. The risk necessitates a solution in which secure, targeted access to data is provided to authorized users for their unique tasks.
Protopia AI provides that solution. Our core technology enables us to reason about the extent to which features of a data record impact a given machine-learning model’s outcome. Using this information, Protopia mathematically perturbs features according to their level of importance to the outcome of a target task. This enables our clients to minimize the data they provide to any given internal or external consumer of data, exposing only the bare minimum a consumer’s task requires, whether for validating their model or offering predictions based upon a data record. The figure below illustrates what this entails at a high level. Protopia AI’s solution enables each consumer to get their curated view of each data record they need access to for extracting value for the Enterprise.
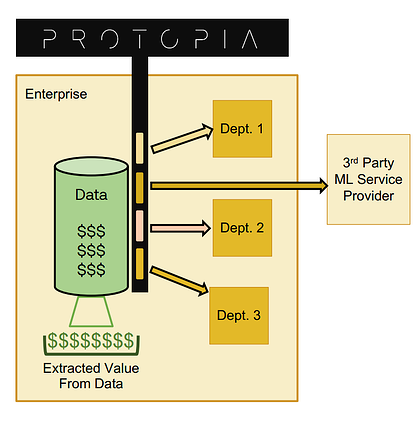
Clients using Protopia AI’s solution realize several organizational benefits. Enterprise clients can maximize the value they extract from their AI data by:
- removing restrictions imposed by external regulations or internal risk governance entities and
- accelerating the deployment of AI solutions; in effect, they “go faster by having more precise breaks.”
Clients can also minimize concerns of unintended inferences and privacy violations, even as the organization avoids restrictions and accelerates AI solution deployment by providing data to AI consumers on a “need-to-know” basis.
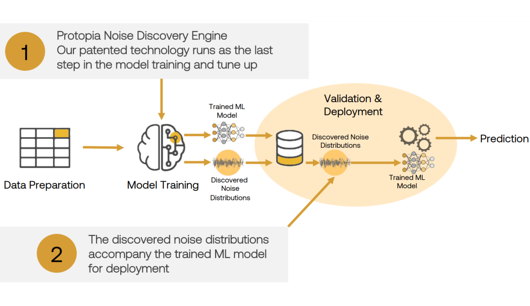
The diagram shown below demonstrates how the solution easily fits into existing machine-learning pipelines. Our patented noise discovery engine runs as the last-step optimization of a client’s existing training pipeline. A client’s training output, originally just a trained ML model, is validated and deployed together with Protopia Discovered Noise Distributions. The discovered noise distributions are used to obfuscate real data before that data is sent to the internal or external data consumer, where it will be used to validate the trained model or to infer something of benefit to the enterprise.
Intrigued? If you’d like to see Protopia’s solution at work, we’ve created a DIY demo that allows you to play around with an ML task for face detection. The model is pre-trained for face detection with the associated noise distributions. Simply go here, provide us your email, and we will send you a Github invitation. Once there, you’ll find instructions on how to run the deployment and feed your own input data to see what your data looks like with Protopia’s solution and without it.
If you find the DIY demo further piques your interest, we would like to invite you to try the solution with your own machine-learning task. If you schedule a brief call here, we’ll connect about your use case. We’ll give you access to a trial version of our solution so you can see just how Protopia will handle your own machine learning task.